


שלום כולם, וברוכים הבאים לאלישע והזוויות, עונה שניה פרק מספר 6!
עבר יחסית הרבה זמן מאז הפרק הקודם. קודם היו החגים, ואז הגיע "אחרי החגים"... אתם יודעים איך זה. בכל אופן, אני חזרתי ומקווה שמעתה והלאה הפרקים יצאו באופן סדיר. כמו כן, חשבתי לשתף שעשיתי ראיון עם אלכס בקאלו בערוץ TOV על נושא הפרוגרסיביות - ערוץ אינטרנטי, למי שלא מכיר - אז אתם מוזמנים לצפות!
בתקופה האחרונה, AI נמצא בכל מקום, והמונח הפשוט הזה, בינה מלאכותית, מתחיל לאבד מהזוהר שלו. הבאז החדש, הדבר שאליו כולם נושאים את עיניהם, הוא לממש בשטח AGI, ראשי תיבות של Artificial General Intelligence, "בינה מלאכותית כללית". אם יש לנו היום מערכות AI שיודעות לדבר, וכאלו שיודעות לכתוב, וכאלו אחרות שיודעות לצייר, וכן הלאה, AGI אמורה להיות מערכת שיודעת לעשות את כל הדברים הללו יחד, ובאופן אינטרגרטיבי. בעצם, השאיפה כאן היא לייצר משהו דמוי המוח האנושי, שמסוגל גם הוא לעשות את כל הדברים הללו. סם אלטמן, אחד המייסדים של OpenAI, החברה שהביאה לנו את GPT, הגדיר זאת כך:
"לדעתי יש הרבה הגדרות סבירות ל-AGI, אבל עבורי, מדובר במשהו ששקול לאדם חציוני. יצור ממוחשב שתוכל לשכור כעובד בחברה לעבודה מרחוק, והוא יוכל לעשות כל מה שעובד רגיל יכול לעשות. זה כולל ללמוד להיות רופא, ללמוד לכתוב קוד - יש הרבה דברים שאדם חציוני יכול לעשות טוב. לדעתי מדובר במטא-יכולת כזו, של ללמוד דברים חדשים ולהתמקצע בכל דבר שאתה צריך."
כפי שבוודאי שמתם לב, ההגדרה של אלטמן זו הרחבה של מבחן טיורינג: הוא רוצה מכונה שדרך ממשק המחשב הוא יחווה אותה כאילו היא אדם חציוני. זו "הרחבה", כמובן, שכן טיורינג דיבר רק על שיחת צ'ט טקסטואלי, בעוד אלטמן מניח שהמכונה תוכל לעשות עוד הרבה דברים שבני אדם עושים: לשרטט דיאגרמות, להבין מה קורה בוידאו, וכן הלאה. לצורה שבה אלטמן מדבר יש חשיבות נוספת כמובן. הוא לא רק אומר שהיכולות הללו יהיו קיימות, אלא הוא מדבר על המחשב כעל "עובד" אמיתי בחברה כלשהי. בחזונו, כך נראה, המחשבים החזקים הללו יוכלו להחליף אנשים ממש בתפקידים שלמים.
אין ספק שכמו כל מהפכה טכנולוגית, הכניסה של AI לתעשייה משנה ותמשיך לשנות את עולם העבודה. אבל מה שנרמז בדבריו של אלטמן הוא, כך נראה, משהו עמוק יותר. לומר על מחשב שהוא יוכל לעשות "כל מה שעובד רגיל יכול לעשות" משמעו שהתפוקה של המחשב והתפוקה של בן האנוש יהיו שקולות באיכותן. אלתמן מדבר על כך שכמו שאדם יכול ללמוד לעשות כל מני דברים שונים זה מזה, כך גם ה-AGI יוכל להתאים את עצמו לכל משימה. בעצם, הוא רומז כאן שלא רק במשימות נתונות יהיה המחשב מוכשר, אלא שהפוטנציאל שלו יהיה שקול לזה של בן אדם, בכל מובן שדורש חשיבה והבנת העולם.
היעד הזה הוא כמובן שאפתני, ובשלב הזה בעונה אני רוצה לשאול - האם זה נכון? האם באמת נגיע לרגע שבו הפוטנציאל של המחשב יהיה שקול לזה של בן האנוש, או שמא תמיד יהיה צורך בבני אדם איפהשהוא בתהליך? בפרקים הבאים אני אנסה לשרטט עבורכם - ועבורי גם - כמה מן הגבולות המעניינים שיהיו, לפחות לדעתי, לטכנולוגיות החדשות שסובבות אותנו, וזאת גם כשחושבים מה יקרה עשור או שניים קדימה.
לומר משהו על איפה נהיה עוד עשרים שנה - זה קצת יומרני, אני יודע. אבל כפי שתראו, גם אם אני לא יכול להוכיח באופן מוחלט את התחזיות שלי, נקודות התורפה שנצביע עליהן בפרקים הבאים הינן עמוקות ביותר ונוגעות בדברים שורשיים מאד. אז תנו לי לתקן את ההימור שלי ולומר שאם בעוד עשרים שנה הבעיות שנדבר עליהם היום ובפרקים הבאים יפתרו, זה כנראה אומר ששינינו כמה דברים משמעותיים באיך שאנו בונים את ה-AI שלנו. הדרך שאנו צועדים בה היום היא אמנם בעלת עוצמה גדולה, אבל בלי לטפל בחסרונות שלה לא נוכל לפרוץ חסמים מסויימים.
זה בגדול לאן אנו הולכים. ספיציפית בפרק הזה אני ארצה לטעון שהצורך בדאטה איכותי ובכמויות גדולות והולכות הוא גם אחד מאזורי החולשה של הטכנולוגיה הקיימת; וספיציפית, הרעב התמידי של המערכות הללו לעוד ועוד דאטה, מרמז על הצורך שלהן לחפות על מה שאין בהן באמת: חשיבה אנושית.
אז יאללה, בואו נתחיל.
איך מייצרים AI? כפי שאתם זוכרים מהפרקים הקודמים, לוקחים מכונה שיודעת ללמוד מדוגמאות, ועל ידי חשיפה להמון דוגמאות היא לומדת איך אנו מצפים ממנה להתנהג. כמה זה "המון דוגמאות"? הכל תלוי בסיטואציה, כמובן. נניח, אוסף התמונות המפורסם ImageNet מכיל כ-14 מיליון תמונות של כל מני עצמים בעולם, ושלצידם תיוג שקובע מהו העצם המופיע בתמונה: חתול, רמזור, וכן הלאה. האוסף הזה היה אחד האוספים הגדולים הראשונים של דאטה לטובת אימון AI, וזו היתה משימה ממש לא טריוויאלית ליצור אותו. בעוד שלארגן ולאסוף הרבה תמונות זה דבר יחסית קל, בהינתן הגישה האוניברסלית לאינטרנט, האתגר הקשה היה להשיג את התיוגים, כלומר לדעת מה מופיע בתמונה. תזכרו שהתיוגים זה החלק החשוב - תהליך הלמידה הוא שמראים למכונה תמונה, היא מנחשת מה יש שם, ואז נותנים לה משוב - או "כל הכבוד", או "נו-נו-נו, התשובה האמיתית היא (השלם את החסר)". בלי התיוגים, אין יכולת לתת משוב.

אז מאין הגיעו התיוגים ב-ImageNet, או בכלל באוספים כאלו של דאטה? בצורה זו או אחרת, בני אדם מתייגים אותם. בחלק ניכר מהמקרים מדובר באנשים שפשוט יושבים מול מסך מחשב במשך שעות ומתייגים תמונה-אחר-תמונה, וידאו-אחר-וידאו. לצד זה יש גם גרסאות יצירתיות יותר של השגת תיוגים. נניח, כמו שמשחילים לכולנו פרסומות בסרטוני יוטוב, יש חברות שמשחילות משימות תיוג כאלו לתוך משחקי מחשב, והשחקן שנענה לאתגר התיוג מקבל בונוסים במשחק. בשורה התחתונה, מילוני אנשים מועסקים בצורה זו או אחרת ברחבי העולם בבניית אוספים של דאטה מתוייג.
עולם התיוגים הוא עולם חדש, מעניין ולפעמים גם בעייתי. השכר של אלו שעובדים בתחום נמוך, וחלק ממשימות התיוג דורשות חשיפה לתכנים קשים כמו אלימות ופורנו. מאידך, רק בזכות התיוג שהם מספקים לחברות ההייטק אנחנו יכולים לשוטט ברשתות חברתיות בלי שמישהו ישחיל לנו תכנים שכאלו לפיד. אז, למי שמעוניין ללמוד יותר על תחום העיסוק הזה, אני מצרף כאן סרטון תיעודי של צוות צילום שחקר את הנושא. בסרט כל התמונות הגרפיות מצונזרות, אז אין לכם מה לדאוג בהקשר הזה אם דאגתם.
בכל אופן, כפי שאתם יכולים לדמיין, לארגן "פס ייצור של דאטה מתוייג על ידי בני אנוש" זה לא דבר קל, ומהווה כאב ראש גדול עבור התעשייה. קודם כל, כמו בהרבה תעשיות, התשלום על משכורות לבני אדם תופס נתח נכבד מעלות התפעול. שנית, יש בעיה מהותית של בקרת איכות. אם אתם שוכרים אנשים לתייג מליוני תמונות, איך תדעו שהמתייגים עשו עבודה טובה בתיוג? איך תזהו טעויות ורמאויות, או אנשים עצלנים שלא מקפידים על דיוק? הבעיות הללו הינן רק כמה מהבעיות שכל חברה שרוצה לקבל דאטה מתוייג ואיכותי צריכה להתמודד איתן.
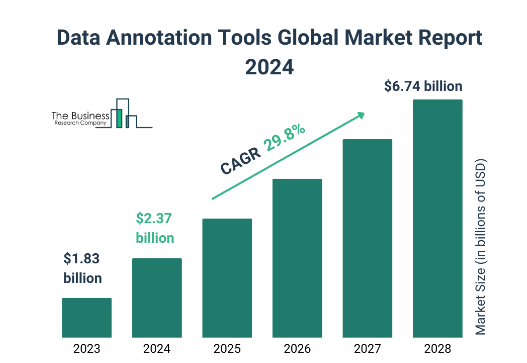
בשל הצורך בהמון דאטה מצד אחד, ועלויות גבוהות בייצור ואיסוף הדאטה הזה מצד שני, הקהילה המדעית והטכנולוגית כל הזמן מחפשת קיצורי דרך, דרכים להמעיט את ההישענות שלהם על דאטה אנושי, ובמקום זה להשתמש בדאטה סינתטי - תיוגים שמחשבים מייצרים באופן אוטומטי, מחשבים שמייצרים דאטה מתוייג מראש לפי הזמנה, או שיטות ללמוד על העולם ללא צורך בתיוגים מראש, מה שקוראים בעגה המקצועית Self Supervised Learning, למידה בבקרה עצמית. אבל על אף המאמצים הללו, נראה שהצרכים בתיוג אנושי רק גדלים משנה לשנה. על פי מכון מחקר אחד שראיתי, אם ב-2023 שוק התיוגים תפס כ-1.8 מיליארד דולר, התחזית שלהם היא שב-2028 השוק יגדל ליותר מ-6 מיליארד.
כל הדברים הללו אמורים לעורר אצלנו ספק מסויים, אפילו לא קטן במיוחד, לגביי חזון ה-AGI לפי סאם אלטמן. אם AGI אמור להיות מסוגל להחליף בני אדם באופן מוחלט בתפקידי עבודה, האם הוא לא אמור להיות מסוגל לתייג דאטה ולהגיד מה קורה בו? תיוג של דאטה נשמע כמו משימה של אדם חציוני, הלא כן? מרגיש שמשהו קצת אחר קורה כאן. כפי שאומרים - "כאן חשדתי": העובדה שאנחנו לא יכולים להישען על מכונות כדי לתייג לנו דאטה מרמזת, אולי, על משהו שחסר במערכות הקיימות. אז - מהו?
כדי לענות על השאלה הזו, יעזור שנכיר את עולם התיוגים קצת יותר מקרוב. לפני כמה שנים קראתי כתבה בנושא תעשיית התיוג, וסיפור ששיתף הכותב, Josh Dzeiza, תפס את תשומת ליבי.
כחלק מעבודת התחקיר שלו, ג'וש נרשם לאחת מחברות התיוג כדי לחוות את התפקיד באופן ישיר. המשימה הראשונה שקיבל היתה לעבור על תמונות ולתייג האם ואיפה מופיעים בגדים בתמונה. ההוראות דייקו עוד יותר את המשימה: הוא התבקש לתייג רק "בגדים אמיתיים שיכולים להילבש על ידי אנשים אמיתיים". בגדי בובות, בא נאמר, לא כלולים ברשימה.
קחו כמה שניות לחשוב על המשימה הזו, ותוודאו שאתם מבינים את הכלל. האם אתם מרגישים בנוח לבצע משימה כזו עבור תשלום ראוי? אני מהמר שרובכם תגידו "כן, נשמע די קל". ולכן, עם התחושה הזו, עם הביטחון העצמי הזה, קיראו את החוויה של ג'וש:
משוכנע ביכולתי להבחין בין בגדים אמיתיים שניתנים ללבישה על ידי אנשים אמיתיים לבין בגדים שאינם אמיתיים שלא ניתן ללבוש, ניגשתי למבחן ההתקבלות למערכת. מיד על ההתחלה, המערכת זרקה לכיווני אתגר אונטולוגי: תמונה ובה מגזין, כשהמגזין מציג תצלומים של נשים בשמלות. האם צילום של בגד הוא בגד אמיתי? "לא", חשבתי לתומי, "כי אדם לא יכול ללבוש צילום של בגד." אבל המערכת הודיעה לי שטעות בידי! מבחינת הבינה המלאכותית, תצלומים של בגדים אמיתיים הם בגדים אמיתיים.
אחר כך הגיעה תמונה של אישה בחדר שינה, מואר בעמעום, המְצָלֶמת סֶלפי בעומדה לפני מראָה באורֶך מלא. החולצה והמכנסיים הקצרים שהיא לובשת הם אמיתיים, כמובן, אבל מה לגבי ההשתקפות שלהם? המערכת קבעה - גם כן בגדים אמיתיים! מבחינת המערכת, השתקפויות של בגדים אמיתיים הם גם בגדים אמיתיים.
סיפור חביב, נכון? וזה לא נגמר שם. ג'וש מתאר איך לאחר שעבר את שלב הסינון הראשוני בתהליך ביצוע המשימה, הוא קיבל את ההוראות המלאות, ואלו היו באורך של לא פחות מ-43 דפים (!!) גדושים בהוראות מפורטות ותמונות להדגמה. כפי שהוא כותב, נעליים נחשבו בגדים אבל לא כפכפים; טייטס כן אבל גרביונים לא; תחפושות בפנים אבל שיריון אבירים - בחוץ; ואם יש תמונה של מזוודה פתוחה ובה בגדים מקופלים - אין לסמן אותם. בקיצור, בלאגן אחד גדול.
מה קורה כאן? בואו נפרק את הסיפור שמאחורי הסיפור. זה מתחיל בכך שהמציאות מבולגנת ורועשת, וההוראות באו להתמודד עם הבלאגן הרועש הזה. Milagros Miceli, חוקרת גרמניה שמצוטטת במאמר, מסבירה שהלקוח רוצה את התיוג כדי לשרת את המוצר או השירות שלו, ומתוך זה נגזרים ההוראות. חברות התיוג צריכות לאפיין במדוייק מה לתייג כדי שהלקוח יהיה מרוצה, וכפי שהיא מצוטטת בכתבה, הם "מנסים לפשט מציאות מורכבת ומרובת-רבדים, לכדי משהו שמכונָה ממש טיפשה תוכל להבין". הדברים אולי יזכירו לכם את מה שהערתי בפרק הרביעי, לגביי זה שאפילו שבני אדם מסוגלים לזהות חתולים ביתר קלות, זה מאד קשה לנסח במדוייק סדרת הוראות לזיהוי חתולים, ומי שינסה - יפול לבור שלא יצא ממנו. אתם יודעים איך נראה בור שכזה? בדיוק - הוא נראה כמו 43 דפים של הוראות מפורטות, שמנסות לתחם באופן עיקבי מציאות בלאגניסטית, ושאת העיקביות שבה קשה הרבה פעמים לראות. רואים אם כן, עד כמה משימת התיוג היא קשה - קשה למתייגים, כמובן, אבל גם קשה לאלו שבאים להגדיר אותה. זהו המסר הראשון העולה מן הסיפור.
אבל מעבר לקושי הטכני באיפיון משימה נתונה, טמון כאן גם מסר נוסף, והוא שהמציאות עצמה היא כל כך מורכבת ומרובדת, שתמיד יש המון דרכים להסתכל עליה, הרבה יותר ממה שאנו מדמיינים במחשבה ראשונה. בניגוד לאינטואיצה שלנו, מסתבר שהמושג "לבוש שאנשים לובשים" הוא רב-משמעי, ואנחנו נבין אותו אחרת בהקשרים שונים. או נניח שהתבקשתם לסמן בתמונה אנשים שלובשים חולצה אדומה. מה תעשו עם חולצת פסים, או חולצה כחולה עם כיס אדום? אין תשובה אחת נכונה.
אם נרצה להיות מדוייקים יותר, מה שקובע מהי התשובה הנכונה במקרה נתון הוא המטרה שלשמה אנו מתייגים את הדברים, ואפשר להדגים זאת עם דוגמה פשוטה. נניח שהתבקשתם לעבור על הוידאו של מצלמות האבטחה בקניון הקרוב למקום מגוריכם, ולתייג את כל כלי נשק שמופיעים בפְרֶיים. ועכשיו לשאלה: האם אני רוצה לתייג גם חולצות עם הדפסים של רמבו? מה לגביי דונלד דאק המחזיק באקדח מצוייר? האם צריך לסמן ילד שהתחפש לאינדיאני ומחזיק חץ-וקשת? ומה בעניין השתקפויות של אקדח במראה?
התשובה היא שהכל תלוי במיהו הלקוח ומה מעניין אותו. אם הלקוח הוא המשטרה, אז סביר שהיא מעוניינת בכל דבר שיכול להוות סכנה בטחונית למבקרי הקניון, ואז חולצות וסרטים מצויירים לא רלוונטים אבל השתקפויות במראות - סופר רלוונטי. מחר, יגיע פרופסור למדעי החברה שחוקר את המוטיבים המיליטנטים בחברה הישראלית, ומבחינתו כל הוריאציות שהזכרתי יכולות להיות סופר-רלוונטיות.
אז, אם נמשיך את הקו הזה ונשאל - מהי כמות הצרכים האנושיים? התשובה היא ברורה וידועה: פלוס-מינוס אינסוף. כוחות השוק והחברה מייצרים כל הזמן צרכים חדשים. כל עוד המציאות והאופנים שאפשר להסתכל עליה היא ימשיכו להתרחב ללא סוף, התיוג של תמונה היום לא יספיק לנו לכל צרכי העתיד, ולאורך זמן, נזדקק כל הזמן לעוד ועוד תיוגים. ולכן כנראה שעבודת התיוג האנושית לעולם לא תסתיים.

אז דיברנו על מורכבות התיוג, ודיברנו על ריבוי הצרכים, אבל שווה להקדיש גם שתי דקות לסיבה נוספת שבגינה תיוגים ימשיכו להיות חלק מתעשיית ה-AI, והיא התנועה של התחום גם לתחומים מופשטים ועמוקים יותר מסתם זיהוי חפצים בתמונה. קחו לדוגמה את האוסף המכונה AffectNet, שמכיל כחצי מיליון תמונות של פרצופים, ושלגביי כל תמונה מישהו הסתכל בפרצוף שניבט ממנה ותייג את התחושה שמובעת בפרצוף הזה. הסימונים נבחרו מתוך 8 קטגוריות בלבד של תחושות, דברים כמו נייטרלי, שמחה, עצב וכן הלאה.
עכשיו, זה נשמע כמו אוסף מגניב, ואולי כזה שאפשר לאמן לפיו מחשבים שיזהו רגשות לפי פרצופים. אבל נראה לי ברור לכולנו שיש כאן משימה שונה לגמרי מאשר תיוג של חתולים ורמזורים בתמונות. קודם כל, בני אדם שונים ותרבויות שונות מביעים רגשות באופן שונה בפרצוף שלהם. שנית, מאותה הסיבה גם זהות המתייג יכולה להשפיע על התיוג - מתייג אנגלי ומתייג יפני יתייגו דברים אחרת, אני מהמר. ולסיום, והכי חשוב, תוסיפו את זה שמחר יכול להגיע מישהו אחר, אולי מתרבות אחרת, ולהציע ששמונה הקטגוריות אינן נכונות או מדוייקות, והפסיכולוגיה האנושית דווקא מחייבת שנקטלג ל-11 קטגוריות. מכל הסיבות הללו, עבודת התיוג לא תסתיים לעולם.

אפשר להמשיך ולהרחיב, אבל נדמה לי שהעניין ברור: מחשבים זקוקים לתיוגים הללו כדי לשדרג את היכולות שלהם, ואפילו שיש שרוצים להיפטר מהגורם האנושי בתהליך התיוג, הצורך בבני אדם רק מתרחב. ואולי באמת יבוא יום שבו נוכל להפסיק לייצר עוד ועוד דאטה אנושי, אבל ממה שראינו דווקא נראה שההיפך הוא המקרה הסביר יותר: כיוון שיש אינסוף דרכים להסתכל על המציאות, ורק בני אדם יכולים לומר למחשבים איזה מכל הדרכים הללו הוא מעניין, התיוג האנושי לא הולך לשום מקום.
המעמסה של יצירת כמויות דאטה גדולות היא בעיה חדשה יחסית, כזו שקיימת במיוחד מאז שעולם ה-AI הבין איך אפשר למנף כמויות גדולות של דאטה. אבל בעומקה מדובר דווקא בבעיה ישנה ומוכרת. כבר באמצע המאה ה-20, התגלתה בעיה בחקר ה-AI ושמה "בעיית המיסגור", The Frame Problem. חוקרי הבינה המלאכותית דאז התקשו בפיצוח אגוז מעצבן: איך מסבירים למחשב אילו עובדות רלוונטיות למשימה שלו ואילו לא? בהינתן בעיה כלשהי, איך הוא אמור לדעת שמידע X יכול לעזור לפתור את בעיה Y, או שכיוון Z לא שווה בדיקה? איך הוא צריך לדעת שאין קשר בין הגירוד שיש לי בראש לבין מזג האוויר ביפן? הנה, תשמעו קטע קטן מדבריו של פרופסור מוריי שנאהאן, פרופסור ב-Imperial College of London וחוקר בגוגל, בהרצאה שנתן לפני כעשור על הנושא:
באופן כללי יותר, כיצד יכולה תוכנת מחשב לזהות את קבוצת האמונות הרלוונטיות לתפקוד קוגניטיבי כלשהו? נניח, תחשבו על מי שחשב על זה שהמבנה של האטום דומה למבנה של מערכת השמש. איך מישהו אי פעם חשב על הכיוון הזה? יש כאן תהליך לא טריוויאלי, שמקשר בין שני דברים שונים לחלוטין. כיצד אפשר להדריך תוכנת מחשב לעשות דבר שכזה?... הבעיה היא, שכל דבר עשוי להיות קשור לכל דבר אחר!
ובהחלט, מדובר בבעיה קשה. בגדול, הדרך שבה פותרים אותה היא שבני אדם מכוונים את המכונות ומצמצמים עבורם את החתכים של העולם שמעניינים מראש, ואת השאר המכונות פותרות באמצעים הסתברותיים, מנחשים משהו על בסיס העבר ולומדים מטעויות. החלק הראשון, ההכוונה האנושית, מגיע בכל מני צורות: הוראות מפורשות בקוד של המחשב, בחירת החיישנים שהמערכת תקבל ואלו שלא תקבל, וגם הרבה מידע שעובר למחשב ברמיזה, דרך הדאטה המתוייג והאופן שבו הוא מאורגן. אבל תמיד יש מעורבות של האדם, ובלי בני אדם שיתנו את המיסגור בצורה כלשהי, כל הסיפור הזה לא יעבוד.
בואו נעמיק עוד קומה בתובנה שבפנינו. מה בדיוק התרומה האנושית פה בסיפור הזה של המיסגור? עד היום דיברנו הרבה על תבונה, אבל ממה מורכבת התבונה הזו? חלק מזה הוא בוודאי מה שאנו קוראים אינטלגנציה, חשיבה לוגית ורציונלית. אבל האם זה הכל?
נראה שמרכיב נוסף וקריטי הוא בעיקר משהו אחר: סוג של "common sense" , ובמיוחד common sense אנושי - דברים שבני אדם יודעים באופן אינטואטיבי שהם טובים או רעים, רצויים או דחויים. תחשבו על זה שמה שהופך דבר לרצוי או פגום איננו משהו במציאות הגולמית, אלא רק האופן שבו המציאות הזו מתייחסת ומשמשת את האדם. כוס פלסטיק שלמה וחזקה טובה יותר מכוס פלסטיק שנקרעה לגזרים רק בגלל שעבור בני אדם, לכוס השלמה יש שימוש שאין לזו שנקרעה. וכיוון שכל המחשבים הללו נבנים כדי לשרת את צרכי בני האדם, אנחנו חייבים לוודא שהוא, המחשב, רואה את העולם באותו אופן שאנחנו רואים אותו. אפשר לראות גם איך הדברים משתלבים, כרגיל, במבחן טיורינג: מחשב שאינו מבין את העולם דרך עיניים אנושיות, ייכשל במבחן טיורינג די מהר.
במילים אחרות, בעיית המיסגור משקפת משהו אמיתי - באמת יש אינסוף דרכים לאפיין ולהממשק עם העולם. כשאנו מספקים למחשבים הרבה דאטה, אנחנו בעצם מספרים להם לא רק על העולם, אלא על איך אנחנו, בני האדם, תופסים את העולם.
וכאן אנו מגיעים לנקודה שבה פתחנו את הפרק היום. שאלתי בתחילת הפרק, האם יש סיכוי שאותו AGI יוכל להתנהל בעולם העבודה ללא מגע יד אדם. לאור מה שראינו עכשיו, הכל תלוי במה שקורה שם מתחת למכסה המנוע של המחשב. אם המחשב היה מצליח לזקק מכל הדאטה שהוא ראה את אופן החשיבה האנושי, לייצר ממש מוח אנושי-סינתטי, אז משלב מסויים והלאה הוא לא היה צריך לקבל עוד הדרכות, ולא היה צריך לייצר עבורו עוד ועוד דאטה מתוייג. כמוני וכמוכם, הוא היה מסתכל בעולם דרך משקפיים אנושיות-סינתטיות, ומבין לבד איך אנשים רואים את העולם. אבל כפי שראינו, צרכי התיוג כל הזמן גדלים, מה שאומר שלפחות נכון להיום, נראה שהמחשב איננו באמת מבין איך אנו רואים את העולם.
אבל, אם הוא לא באמת מבין איך אנחנו רואים את העולם, אז איך המחשב מצליח היום לכתוב טקסטים שנשמעים מאד משכנעים, כאילו בן אדם כתב אותם? משהו משמעותי בכל זאת קורה שם, נכון? ובכן, להבנתי קורה שם משהו אחר. אני ארחיב על זה בפרקים הבאים, וכרגע רק אתן את זה בקצרה: במקום ללמוד איך בני אדם חושבים ורואים את המציאות, המכונות מחלצות מן הדאטה שנתנו להם סוג של "צילום מצב" של החשיבה האנושית ברגע נתון. הצילום הזה הוא ברזולוציה גבוהה מספיק ש-GPT וחבר מרעיו יכולים לחקות התנהלות ויצירתיות אנושית באופן מוגבל, אבל הן לא יורדות לעומק התפיסה האנושית את המציאות. ולכן לאורך זמן, וללא מעורבות של אנשים שיזרימו לו עוד מידע ויעצבו אותו מחדש, המחשב היה מאבד מהרלוונטיות שלו.
הרעב המתמיד לעוד דאטה חושף בפנינו, אם כן, שנתנו ל-AI המון דגים, אבל כנראה שעדיין לא לימדנו אותו לדוג לבד.
אז, זהו להיום. הנקודה העיקרית שרציתי להעביר כאן היא שהמציאות היא אינסופית במורכבות שלה, ובני האדם מעוניינים רק בחתך קטן מכל מה שיש שם בחוץ. כיוון שאפילו החתך הזה מתפתח כל הזמן, האופן שבו GPT ודומיו מתמודדים עם ההתפתחות הזו יכול לרמז משהו על מה שבאמת הם עושים. וכיוון שכרגע נראה שה-AI זקוק כל הזמן לעוד ועוד דאטה, נראה שיש כאן יותר שכפול של מידע אנושי סטטי מאשר עיצוב חשיבה אנושית עצמאית ודינמית בתוך המכונה. כמובן, אפשר לחשוב אחרת. יש כאלו שבטוחים שהכל עניין של זמן, וש-GPT גרסה 10 תצליח לממש חשיבה אנושית מלאה. לאלוקים פתרונים, כפי שאומר הפתגם המפורסם, ואתם מוזמנים לבחור את העמדה שלכם בעניין.
אבל מה שראינו היום הוא רק הצעד הראשון. בפעם הבאה נדבר על סדרת מחקרים מהשנה האחרונה ששרטטה גבולות נוספים לבינה המלאכותית של GPT, ושגם היא הגיעה למסקנה שאין מנוס מאשר להמשיך כל הזמן להזריק פנימה למערכת ידע אנושי חדש. אבל בעוד הדברים שדיברנו עליהם היום התכווננו למצבים שבהם הידע והשימושים השתנו, הם הראו משהו יותר דרמטי: שאפילו בידע הקיים, הזה שהמכונות אומנו עליו מראש - אפילו שם המכונות נאלצות להישען על בני אדם להמשיך ולייצב את המערכת. אז יש למה לחכות!
ובינתיים…
להתראות, ביי…

